In 2013, a young computational biologist named Yaniv Erlich shocked the research world by showing it was possible to unmask the identities of people listed in anonymous genetic databases using only an Internet connection. Policymakers responded by restricting access to pools of anonymized biomedical genetic data. An NIH official said at the time, “The chances of this happening for most people are small, but they’re not zero.”
Fast-forward five years and the amount of DNA information housed in digital data stores has exploded, with no signs of slowing down. Consumer companies like 23andMe and Ancestry have so far created genetic profiles for more than 12 million people, according to recent industry estimates. Customers who download their own information can then choose to add it to public genealogy websites like GEDmatch, which gained national notoriety earlier this year for its role in leading police to a suspect in the Golden State Killer case.
Those interlocking family trees, connecting people through bits of DNA, have now grown so big that they can be used to find more than half the US population. In fact, according to new research led by Erlich, published today in Science, more than 60 percent of Americans with European ancestry can be identified through their DNA using open genetic genealogy databases, regardless of whether they’ve ever sent in a spit kit.
“The takeaway is it doesn’t matter if you’ve been tested or not tested,” says Erlich, who is now the chief science officer at MyHeritage, the third largest consumer genetic provider behind 23andMe and Ancestry. “You can be identified because the databases already cover such large fractions of the US, at least for European ancestry.”
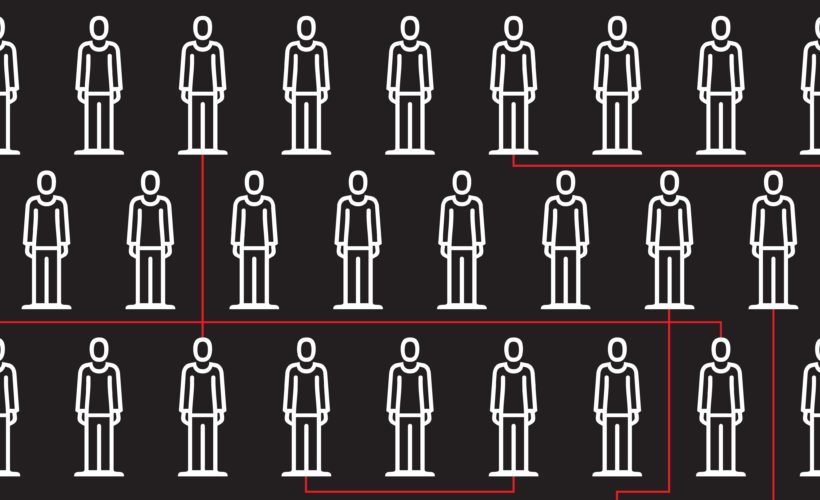
To make these estimates, Erlich and his collaborators at Columbia University and the Hebrew University of Jerusalem analyzed MyHeritage’s dataset of 1.28 million anonymous individuals, which is, like most of the world’s genetic databases, overwhelmingly white. Considering each one of those individuals as a human “target,” they counted the number of relatives with big chunks of matching DNA and found that 60 percent of searches turned up a third cousin or closer. That level of relatedness was all investigators needed to track down the Golden State Killer, and the 17 other cases that have so far been solved with this approach—known to law enforcement as long-range familial searching. To validate their findings, Erlich’s team plugged 30 genetic profiles into GEDmatch and saw similar results, with 76 percent of searches netting relatives in the 3rd cousin or closer range.
That analysis provides a list of around 850 individuals, depending on how prolific a person’s forebears were. But from there, basic demographic information can prune the lineup pretty quickly. Public records indicating where someone lives to within 100 miles cuts the candidate pool in half. Knowing their age to within five years excludes 9 out of 10 of the remaining candidates. The sex, which can be inferred from genetics, gets the list down to around 16 individuals. Knowing the exact birth year could get you down to just one or two people.
To demonstrate how easy it is, the researchers chose an anonymous female subject from the 1000 Genomes Project—an open-access sequencing project—who was married to the man that Erlich had previously identified in his blockbuster 2013 paper. They reformatted her DNA data to resemble a typical consumer genetic profile and uploaded it to GEDmatch. Two relatives popped up, one in North Dakota and one in Wyoming. The match suggested they were distantly related four to six generations back. An hour of public record-combing later and the team had found their husband and wife. From there, the researchers traced the pedigrees of hundreds of descendants to arrive at the identity of their target. All in all, the effort took a single day.
According to Erlich, it won’t be long before it’s possible to do that kind of search on anyone who leaves a bit of DNA lying around. The study found that once a genetic database covers roughly two percent of the adults in a given ethnic population, a match of a third cousin or closer is expected for almost any person of interest. For Americans of European ancestry, who are better represented in genetic and genealogical databases, that threshold could be reached in the next few years if recreational DNA testing continues at its current pace. Two percent is only about four million people, based on the most recent US census data.
Such a resource would greatly expand the number, and kind of people, that law enforcement could have access to when chasing down a lead. Offender databases, where police store the DNA of close to 17 million people—convicted criminals, and in some states, arrestees—skew heavily toward African American and Hispanic populations. Since the earliest days of DNA testing, technological incompatibility between methods has created a practical firewall between offender databases and genetic databases for recreational or research purposes. Law enforcement only collects and analyzes highly variable non-coding portions of the genome, counting up the number of times these “junk” sequences repeat. It’s essentially just a string of numbers—it doesn’t reveal anything personally identifiable on its own. But it’s highly unique to an individual, like a barcode or a fingerprint. And it’s cheap and fast. Perfect for law enforcement purposes.
By contrast, most medical and recreational DNA testing involves either full sequencing or genotype arrays—a collection of changes that each occur at a single location in a gene. These SNPs are the reason you have green eyes or curly hair, or a predisposition for heart disease. They’re also much more useful for finding family members. Because these two types of databases couldn’t communicate, investigators in the Golden State Killer case had to extract DNA from an old crime scene sample, create a SNP profile and upload it to GEDmatch. But now, they won’t even have to do that.
A second paper, published today in Cell, for the first time shows that it’s possible to run long-range familial searches on data from offender databases. Noah Rosenberg’s group at Stanford University had previously shown that you could link up records between the two kinds of databases, by mapping nearby SNPs to the non-coding repeats. Published last year, the research didn’t get much attention. “Crickets,” says Rosenberg. But this latest work, which explores the cross-compatibility of the two databases for finding relatives, has new, profound relevance in the wake of the Golden State Killer case.
“This could be a way of expanding the reach of forensic genetics, potentially for solving even more cold cases,” says Rosenberg. “But at the same time it could be exposing participants in those databases to forensic searches they might not have anticipated.”
According to legal experts, though, the bigger deal is that Rosenberg’s work reveals that there’s much more information contained in a forensic DNA profile than previously thought. That’s because you can use it to accurately predict coding regions of the genome—the green eye, curly hair, heart condition parts. “All the Supreme Court decisions about why existing offender databases don’t violate Fourth Amendment rights are all premised on the presumption that nothing personal can be gleaned from this junk DNA,” says Andrea Roth, director of UC Berkeley’s Center for Law and Technology. “Now that’s all up in the air.”
Rosenberg didn’t release any software with his paper, so it would still take some work to get the computation up and running. But he says anyone with access to multiple databases has all the information they need to start using the technique. Which means those built-in privacy safeguards could crumble quite quickly. The paper is meant as a warning shot, to show policymakers what’s possible with today’s technology, and Rosenberg hopes it spurs much-needed conversations about how genetic information is stored and used going forward.
Erlich and his co-authors went even farther to make recommendations about what changes are necessary to ensure that resources like GEDmatch, which provide an essential service to people looking for long-lost relatives and adoptees searching for their biological families, remain online in a safe capacity. They urged the US Department of Human Services to revise the scope of personally identifiable health information to include anonymized genomic data. And they outlined an encryption strategy that would create a chain of custody, so third-party databases could flag users trying to analyze genetic data that wasn’t their own. But even if every consumer genomics provider bought into this system, it might still not be enough.
“I think the bottom line is now everybody is about to be under genetic surveillance one way or another, unless we regulate the government’s ability to conduct genealogy searches,” says Roth. She suggests a system similar to how California currently regulates more traditional familial searches of its offender databases. They can only be used to investigate violent crimes—homicide or sexual assaults, and the scope of the search is limited, to prevent hundreds of innocent people from being ensnared in the investigation. And there’s an oversight committee that can step in and prevent the inadvertent disclosure of sensitive information that might arise, say that someone’s father isn’t really their father. “That’s what’s so ironic about this,” says Roth. “If you’re the relative of someone in CODIS [the federal offender database], you have a lot more rights to genetic privacy than if you’re a relative of someone in GEDMatch.” With enough DNA, it doesn’t matter if you want to be found or not. Opting out is no longer an option.
More Great WIRED Stories
- So much genetic testing, so few people to explain it to you
- When tech knows you better than you know yourself
- These magical sunglasses block all the screens around you
- All you need to know about online conspiracy theories
- Inside the Black Mirror world of polygraph job screenings
- Looking for more? Sign up for our daily newsletter and never miss our latest and greatest stories
Source:WIRED









